Adaptive Timeout Patterns for Carrier Integration: Dynamic Algorithms That Learn From API Behaviour

Your FedEx integration responds in 200ms on average. Your local courier API takes 5 seconds. DHL varies between 1 and 15 seconds depending on the time of day. Yet most carrier integration middleware still uses static timeout values across all providers. Between Q1 2024 and Q1 2025, average API uptime fell from 99.66% to 99.46%, resulting in 60% more downtime year-over-year, with logistics seeing the sharpest decline in API uptime as providers expanded their digital ecosystems to meet rising demand for real-time tracking, inventory updates, and third-party platform integrations.
Using static, fine tuned timeouts in microservices communication is an anti-pattern as we're in a highly dynamic environment where it's almost impossible to come up with the right timing limitations that work well in every case. When your system attempts to process 10,000 labels during Black Friday, those carefully tuned 30-second timeouts become either too aggressive (causing false failures) or too lenient (allowing cascading delays).
The Cost of Getting Timeouts Wrong
Timeout failures in carrier integration systems cascade differently than typical microservice outages. A premature timeout to FedEx during label generation doesn't just fail that single request - it potentially triggers retry storms, duplicate shipments, and customer service nightmares when packages appear "lost" in tracking systems.
While seemingly modest, this drop translates to an additional 90 minutes of downtime every month — during which e-commerce sites can't process purchases, mobile apps won't load, and critical business applications grind to a halt. For carrier integrations specifically, this translates to failed shipments, incorrect tracking data, and broken promise dates to customers.
Timeout misconfiguration creates problems when services have incompatible timeout settings. If Service A has a 30-second timeout calling Service B, but Service B has a 60-second timeout calling Service C, requests can pile up and exhaust connection pools. In carrier middleware, this manifests when your rate shopping service has a 10-second timeout but your DHL adapter needs 15 seconds during peak European business hours.
Dynamic Timeout Fundamentals for Carrier Integration
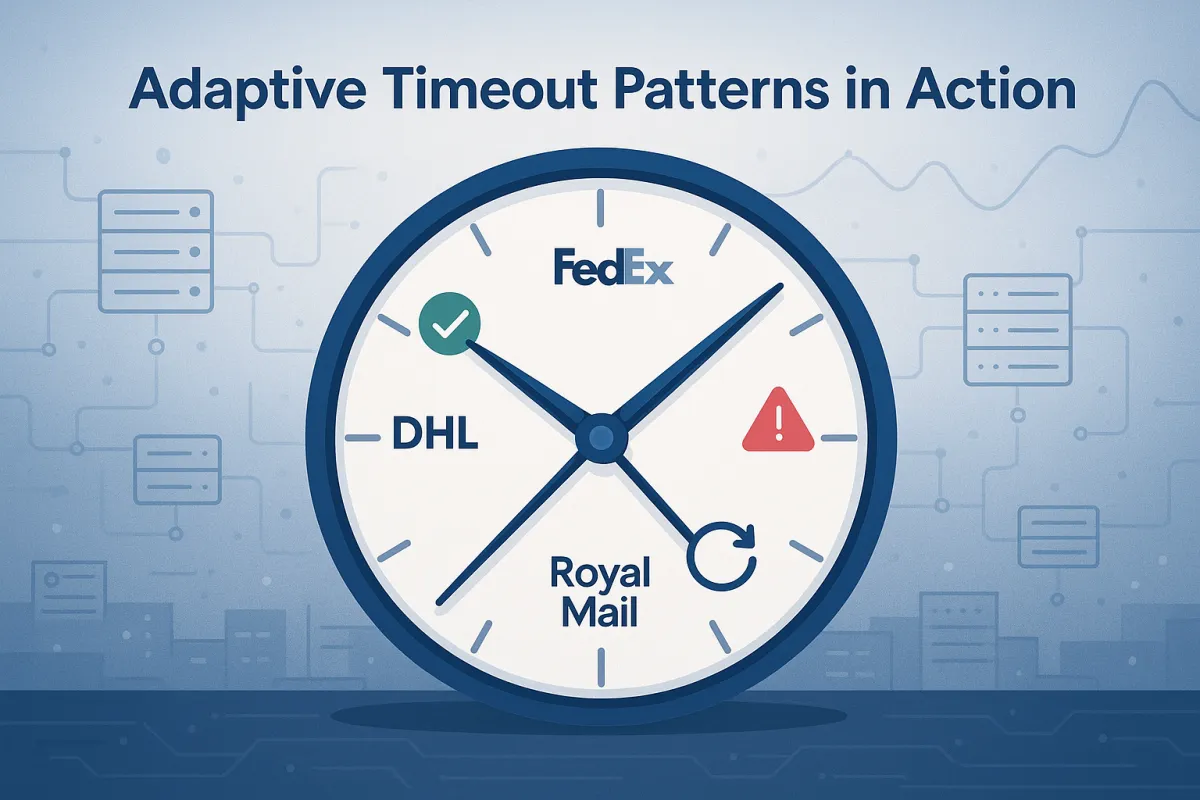
Adaptive timeout patterns move beyond static configuration to responsive algorithms that learn from real API behaviour. These systems continuously monitor response times, error rates, and system load to dynamically adjust timeout thresholds for each carrier integration.
The core metrics for adaptive adjustment include percentile response times (P50, P95, P99), carrier-specific error rates, network conditions, and time-of-day patterns. Rather than setting a universal 30-second timeout, you might discover that UPS APIs respond 40% faster during US overnight hours, while Royal Mail's tracking API becomes unreliable above 3-second response times.
Mathematical foundations typically involve exponential weighted moving averages (EWMA) for response time estimation:
- Current timeout = α × recent_response_time + (1-α) × previous_timeout
- Confidence intervals based on standard deviation of historical response times
- Percentile thresholds where P95 response time + buffer becomes the new timeout
The algorithms we propose aim to be adaptive to both of these forms of change - handling both short-term load variations and long-term implementation changes in carrier APIs. Modern solutions like Cargoson implement such adaptive approaches alongside traditional platforms like nShift and ShipEngine, which typically rely on static configurations.
Algorithm Categories for Carrier API Management
Statistical Models
Statistical approaches focus on analysing historical response time patterns to predict optimal timeout values. Timeout values should be established based on historical performance data. This involves analyzing service performance: gather metrics on how long services typically take to respond under normal load. This can help identify patterns and set realistic thresholds.
Exponential weighted moving averages provide a foundation for real-time adjustment. For each carrier endpoint, you maintain a running average that weights recent observations more heavily:
timeout_new = 0.1 × latest_response + 0.9 × timeout_current
Confidence interval approaches set timeouts based on statistical distribution of response times. If your DHL rate shopping API shows a P95 response time of 4.2 seconds, you might set the timeout to P95 + (2 × standard_deviation) to capture 99.7% of normal responses while avoiding false timeouts.
Machine Learning Approaches
This paper proposes an adaptive rate limiting strategy based on deep reinforcement learning that dynamically balances system throughput and service latency. We design a hybrid architecture combining Deep Q-Network (DQN) and Asynchronous Advantage Actor-Critic (A3C) algorithms, modeling the rate limiting decision process as a Markov Decision Process.
Reinforcement learning models treat timeout optimization as a multi-armed bandit problem. The algorithm learns which timeout values minimize total system cost (combining failed requests, unnecessary waits, and resource consumption) across different carrier conditions.
Pattern recognition systems identify carrier behaviour profiles. Your ML model might discover that Hermes APIs exhibit bimodal response patterns - either sub-second responses or 10+ second delays with little middle ground. This insight allows for timeout strategies that account for binary performance modes rather than assuming normal distributions.
Hybrid Strategies
Production systems typically combine statistical baselines with ML enhancements. You start with EWMA-based timeouts for predictable behaviour, then layer on pattern recognition for anomaly detection and circuit breaker integration.
Fallback mechanisms ensure system stability when adaptive algorithms produce unexpected results. If your ML model suggests a 2-minute timeout for Canada Post (highly unusual), the system falls back to statistical bounds or administrative overrides.
Multi-Tenant Timeout Management
Carrier integration middleware must handle timeout adaptation across multiple customer tenants with different traffic patterns and requirements. A high-volume shipper like Amazon has different timeout tolerance than a boutique retailer sending 50 packages monthly.
Tenant-specific timeout profiles account for individual customer SLAs and usage patterns. Premium customers might receive more aggressive timeout values (faster failure detection) while standard customers accept longer waits for better success rates.
Isolation mechanisms prevent timeout failures in one tenant from affecting others. If Customer A's integration triggers a cascade of DHL timeouts, Customer B's shipments continue with their independent timeout calculations and circuit breaker state.
Fair resource allocation becomes complex when different tenants have different timeout strategies. You need algorithms that prevent one customer's conservative timeout settings from monopolising connection pools during peak periods.
Implementation Architecture
Building adaptive timeout systems requires careful component design. The timeout manager maintains per-carrier, per-endpoint timeout values and adjustment algorithms. Metric collectors gather response time data, error rates, and system resource utilization. Decision engines determine when and how to adjust timeout values based on collected metrics.
Integration points with existing systems require careful planning. Always implement timeouts for external dependencies like databases and microservices. If supported, propagate the timeout value to downstream requests. When building HTTP or gRPC microservices, ensure they accept and adhere to specified timeouts.
Modern platforms like EasyPost, Shippo, and Cargoson provide varying levels of adaptive timeout support. Some offer basic per-carrier configuration while others implement full ML-driven optimization.
Monitoring and observability become critical in adaptive systems. You need dashboards showing current timeout values, adjustment frequency, false timeout rates, and the impact of timeout changes on overall system performance. Without proper visibility, debugging timeout-related issues becomes nearly impossible.
Production Deployment Strategies
Rolling out adaptive timeouts requires gradual introduction to avoid destabilising existing integrations. Implement gradual rollouts for configuration changes. Cascading failures often start with a seemingly innocent timeout adjustment or retry policy change.
A/B testing compares adaptive timeout performance against static baselines. You run 10% of traffic through adaptive algorithms while monitoring success rates, response times, and customer impact. This approach reveals whether adaptive timeouts actually improve system performance or introduce new failure modes.
Alerting thresholds require careful calibration. You want notifications when timeout values change dramatically (potentially indicating system issues) but avoid alert fatigue from normal adaptive adjustments. Setting alerts for timeout changes exceeding 50% of historical values often provides good signal-to-noise ratios.
Common deployment pitfalls include insufficient warmup periods for ML models, inadequate fallback mechanisms, and poor integration with existing circuit breaker patterns. We can say that achieving the fail fast paradigm in microservices by using timeouts is an anti-pattern and you should avoid it. Instead of timeouts, you can apply the circuit-breaker pattern that depends on the success / fail statistics of operations.
Performance Impact and Measurement
Measuring adaptive timeout effectiveness requires careful baseline establishment and multi-dimensional metrics. Success rates, mean response times, P99 latencies, and resource utilization all factor into overall system performance.
Early implementations of adaptive timeout systems in carrier integration show promising results. Organisations report 15-25% reductions in false timeout errors and 10-20% improvements in overall API success rates. Extensive experiments conducted in a Kubernetes cluster environment demonstrate that our approach achieves 23.7% throughput improvement and 31.4% P99 latency reduction in related adaptive algorithms.
Cost analysis must account for both infrastructure overhead (additional monitoring, ML model training) and operational benefits (reduced customer service tickets, improved shipment reliability). The business case typically justifies investment for organisations processing more than 10,000 shipments monthly.
Future Directions and Industry Trends
Edge computing presents opportunities for regional timeout optimization. Deploying adaptive timeout algorithms at CDN edge locations allows for geographic-specific tuning based on local network conditions and carrier performance.
The synergy between serverless architectures and edge computing is driving a significant shift toward more efficient, scalable and responsive API infrastructures, while also enabling greater automation of resource management and scaling. This trend supports more granular timeout management at the edge.
Integration with comprehensive resilience patterns becomes the next evolution. Rather than treating timeouts in isolation, future systems will coordinate timeout adjustment with circuit breaker states, retry policies, and load balancing decisions for holistic resilience management.
Industry movement toward intelligent middleware reflects growing sophistication in API management. Smarter and more adaptable APIs: AI can enhance APIs by optimizing queries, detecting usage patterns, and recommending efficiency improvements for endpoints. Automated API testing: AI models can generate and execute automated tests, reducing errors and ensuring higher-quality service integration.
The future likely holds more standardisation around adaptive timeout APIs, better integration with carrier webhook systems for proactive adjustment, and increased adoption of reinforcement learning for complex multi-carrier optimization scenarios. As carrier integration becomes increasingly business-critical, adaptive timeout patterns will evolve from competitive advantage to operational necessity.