Distributed Rate Limiting for Carrier Integration: Coordination Patterns Beyond Token Buckets

When your multi-carrier platform reaches serious scale, traditional single-node rate limiting starts to break down. You can't just multiply limits by server count and hope requests distribute evenly. One busy integration server gets all the DHL traffic while another sits idle handling UPS requests. Your rate limits become meaningless.
Distributed rate limiting enforces limits consistently across all nodes in a distributed environment, preventing users from bypassing limits by switching servers. This coordination challenge becomes particularly complex in carrier integration software where different carriers have vastly different API behaviours and failure modes.
The Multi-Carrier Coordination Problem
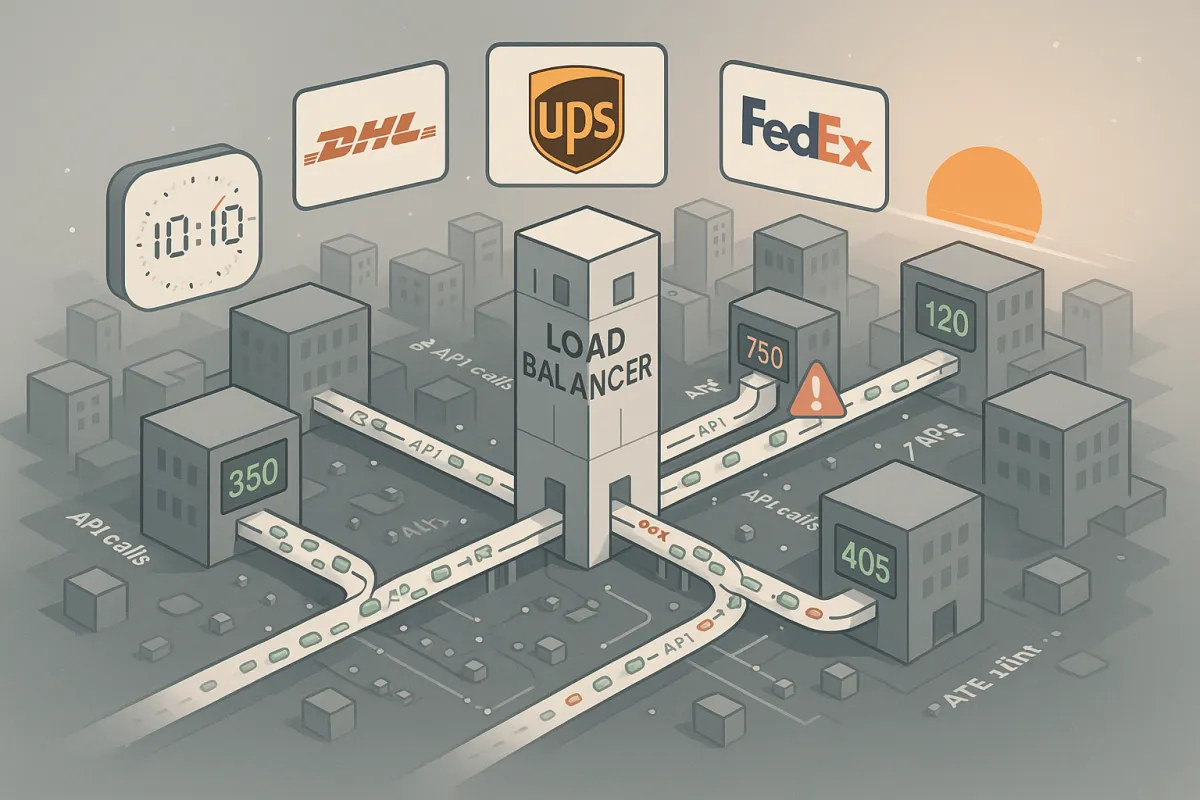
Picture this scenario: your platform routes shipments across twelve carriers, each with distinct rate limits. DHL might allow 100 calls per second for tracking, while UPS limits write operations to 10 calls per second. Meanwhile, your application runs on six instances behind a load balancer that doesn't understand carrier-specific routing.
The load balancer distributes requests randomly. Instance A gets flooded with DHL tracking requests while Instance B handles mostly UPS label creation. Without coordination, Instance A burns through DHL's limit in seconds while Instance B sits under-utilised. Both instances maintain separate counters, neither aware of the other's consumption.
This gets worse during peak periods. Black Friday sees a 300% spike in label requests. In multi-tenant environments, an issue with a single tenant can bring down the entire platform and impact all customers. One shipper's label storm can exhaust carrier quotas for everyone.
Platforms like nShift, EasyPost, and Cargoson all face these coordination challenges. The difference lies in how they synchronise state across instances and adapt to carrier-specific patterns.
State Synchronisation Strategies
Three patterns emerge for sharing rate limit state across distributed instances, each with distinct trade-offs.
Centralised Redis Coordination
A better approach uses centralized data stores like Redis, though this increases latency making requests to the data store. A distributed counter is used, synchronized to a distributed cache so accurate counts across all instances can be maintained.
The key insight: Use Redis EVAL command to execute Lua scripts atomically. The script stores the INCR return value, checks if it equals 1 (first increment), and calls EXPIRE if needed. This prevents race conditions between incrementing counters and setting expiration times.
Local Approximation with Partitioning
If a throttled system allows 500 requests per second, you might create 20 partitions worth 25 requests per second each. A process needing 100 requests might ask for four partitions. Each instance gets a slice of the global limit, trading perfect accuracy for reduced latency.
This works well when traffic distributes evenly but fails during carrier-specific surges. The DHL partition saturates while UPS partitions remain unused.
Hybrid: Redis with Local Buffering
Smart implementations combine both approaches. Maintain precise counts in Redis but allow instances to buffer small amounts locally. The expected calls are made to Redis per second, with atomic increment latency at p95 of 15.7ms, while rate limiting induces only 1 millisecond of latency under load.
Tenant-Aware Rate Limiting Architecture
Multi-tenant systems use rate limiting to shape traffic increases, enforcing quotas at per-tenant or per-workload granularity. This prevents one tenant's traffic surge from affecting others' predictable performance.
The architecture requires hierarchical limit structures. Each tenant gets a primary quota (say, 1000 requests/minute), subdivided by carrier (DHL: 400, UPS: 300, FedEx: 300). Within each carrier, further subdivision by operation type: tracking vs. label creation vs. pickup requests.
Counter keys include tenant ID, endpoint (minus variables), HTTP method, and time window start/end. For example: `tenant_123_dhl_track_GET_1609459200_1609459260`.
This granular approach enables fair resource allocation. When one tenant's workload exceeds limits, the excess portion gets rejected while other workloads continue operating with predictable performance.
Multi-Level Enforcement
Set user-level limits within tenants (25% of tenant's quota), endpoint-specific limits based on resource demands, with stricter controls on write operations compared to read queries.
This creates a protection hierarchy: global platform limits at the top, tenant limits below, then user and operation-specific limits at the bottom. Each level can trigger independently, providing multiple safety nets.
Carrier-Specific Failure Modes and Adaptive Limits
Different carriers exhibit distinct failure patterns that require adaptive rate limiting approaches. UPS APIs typically return clean HTTP 429 responses when limits are exceeded. DHL's APIs sometimes return HTTP 200 with error messages buried in XML. FedEx occasionally returns HTTP 500 during high load periods.
Adaptive limits can dynamically adjust thresholds based on system load. During low usage periods, tenants might temporarily enjoy higher limits, while limits tighten automatically when demand spikes.
Your rate limiter should track carrier-specific error patterns and adjust limits accordingly. When DHL's API starts returning elevated error rates, temporarily reduce request rates by 20% even if you're under the official limit. This prevents cascading failures and maintains service quality.
Peak Season Adaptations
Carrier integration software must handle seasonal traffic patterns. November shipment volumes can reach 3x normal levels. Some carriers increase API limits during peak season, others become more restrictive.
Build seasonality awareness into your rate limiting. Monitor historical patterns and pre-adjust limits based on calendar events. Black Friday deserves different treatment than a random Tuesday in February.
Implementation Patterns: Redis vs In-Memory Hybrid
Redis atomic operations form the backbone of distributed rate limiting. INCR on non-existent keys returns 1, while EXPIRE inside MULTI transactions with INCR creates atomic operations. The worst-case failure is Redis dying between INCR and EXPIRE.
Here's a proven Lua script pattern for atomic increment-and-expire:
local counter = redis.call('INCR', KEYS[1])
if counter == 1 then
redis.call('EXPIRE', KEYS[1], ARGV[1])
end
return counter
Lua scripts execute atomically - no other script or command runs while a script is running, giving the same transactional semantics as MULTI/EXEC.
When to Choose Each Pattern
Use centralised Redis when you need perfect accuracy across all instances. This suits financial or compliance-sensitive operations where every request must be counted precisely.
Choose in-memory approximation for high-throughput scenarios where 5-10% accuracy loss is acceptable. Tracking requests can tolerate approximate limits; label creation cannot.
Hybrid approaches work best for most carrier integration scenarios. Use Redis for critical operations (shipment creation, pickup scheduling) and local approximation for high-volume, low-criticality operations (tracking lookups).
Monitoring and Observability for Distributed Limits
Distributed rate limiting requires comprehensive monitoring to track effectiveness across instances. As API ecosystems expand, rate limiting transforms from simple counting into complex distributed systems challenges, with distributed state management becoming the first major hurdle.
Track these key metrics per carrier and tenant:
Coordination Lag: Time between request arrival and Redis state synchronisation. Spikes indicate Redis performance issues.
False Positive Rates: Requests rejected due to stale local state. High rates suggest coordination problems.
Per-Carrier Success Rates: Percentage of requests that succeed after passing rate limiting. Declining rates indicate your limits are too aggressive or carrier APIs are struggling.
Integrate with existing webhook and circuit breaker monitoring. When DHL's webhook delivery starts failing, your rate limiter should detect increased error rates and adapt accordingly.
Migration Strategies: From Monolith to Distributed
Moving from single-instance to distributed rate limiting requires careful planning. Rate limiter middleware is better architecture because it decouples from other components, scales independently, and can rate limit multiple APIs without separate implementations.
Start with shadow mode: deploy distributed rate limiting alongside existing systems without enforcing limits. Compare decision outcomes to identify discrepancies before switching over.
Use feature flags to gradually roll out distributed limiting per carrier. Begin with low-risk carriers like FedEx tracking, then expand to critical paths like UPS label creation.
Blue/Green Considerations
Rate limiting state doesn't migrate cleanly between deployments. Plan for state consistency during blue/green switches. Consider using carrier-agnostic keys that survive deployment transitions.
Solutions like Cargoson, ProShip, and ClickPost handle these transitions by maintaining separate Redis clusters per deployment environment, then coordinating state transfer during cutover windows.
The key insight: distributed rate limiting isn't just about technical coordination. It's about understanding carrier behaviour, tenant requirements, and operational patterns. Build monitoring first, then implement coordination, then optimise for your specific traffic patterns. Your rate limiter should adapt to your business, not constrain it.