Multi-Tenant Webhook Fan-Out Architecture: Isolating Event Streams Without Sacrificing Delivery Guarantees in Carrier Integration Systems

When you've built multi-tenant carrier integration systems, you quickly learn that traditional webhook patterns break under the unique pressures of shipping APIs. Multi-tenant SaaS applications typically limit tenants to 1M events per day, and anything beyond should be throttled and deferred. But carriers routinely blast you with tracking updates during peak shipping seasons at rates that make those limits look quaint.
The challenge isn't just volume. Every shipping systems architect has faced this conundrum: your carrier integration platform needs real-time webhook delivery, but your stakeholders insist that tracking updates must arrive "in order"—with shipment events following a natural sequence like label created, picked up, in transit, delivered. Meanwhile, one tenant's problematic ocean carrier API can bring down webhook delivery for everyone else.
Multi-Tenant Isolation Requirements in Event Streams
Event Grid works natively with CloudEvents and supports event domains, which are useful for multitenant solutions. This CloudEvents standard adoption provides a foundation for tenant isolation, but implementation requires careful queue topology design.
Database partitioning becomes the first line of defence. Tenant-partitioned webhook subscriptions using PARTITION BY HASH(tenant_id) combined with row-level security policies CREATE POLICY tenant_isolation ON webhook_subscriptions USING (tenant_id = current_setting('app.current_tenant')) ensures data segregation at the storage layer.
But isolation extends beyond data storage. The core architectural challenge in carrier integration webhook systems isn't managing failures—it's preventing one tenant's failures from destroying everyone else's experience, as sharing messaging infrastructure across multiple tenants could expose the entire solution to the Noisy Neighbor issue where one tenant's activity harms others.
Consider this scenario: Tenant A processes 50,000 shipments daily through Maersk's notoriously unreliable API. Without proper isolation, their failed webhook retries consume queue capacity and worker threads that should serve Tenant B's 500 daily parcel shipments, causing Tenant B's customers to complain about delayed notifications while Tenant A's retry storms continue.
Fan-Out Pattern Design for Carrier Events
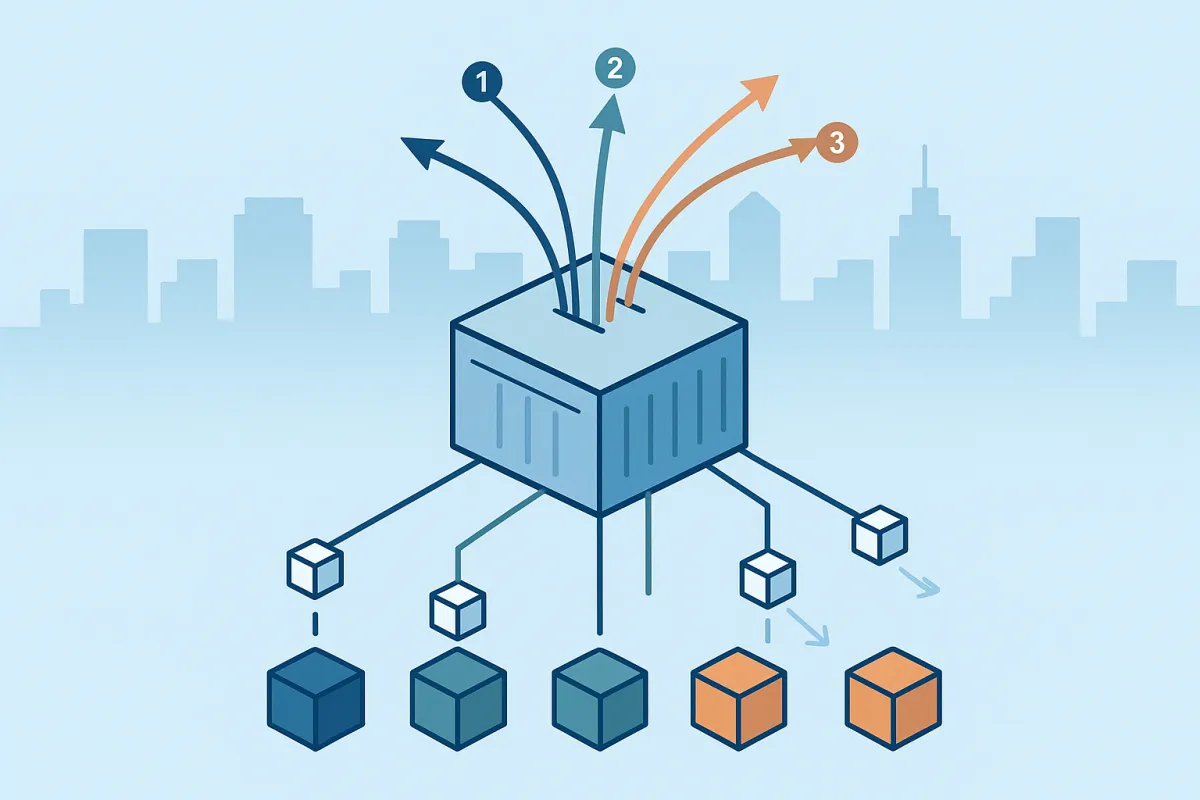
Your system's ability to "fan out" events, duplicating and delivering them to multiple endpoints, plays a pivotal role by offering flexibility, redundancy, load distribution, customization, and scalability for seamless integration and efficient event processing. In carrier integration, a single shipment status change might trigger notifications to warehouse management systems, customer portals, and analytics platforms simultaneously.
Modern solutions are moving beyond simple webhooks. Leading platforms like Stripe, Shopify, and Twilio are moving beyond webhooks-only solutions toward Event Destinations that allow customers to choose where their events are delivered. This pattern works especially well for carrier integrations where different consumers prefer different delivery mechanisms.
Solutions like Cargoson alongside platforms like nShift, EasyPost, and ShipEngine are implementing sophisticated fan-out architectures that can route a single tracking event to multiple destinations based on tenant configuration. The key is maintaining ordering guarantees across this distribution.
Event Ordering Guarantees Across Tenant Boundaries
Webhooks might not always arrive in the exact sequence of occurrence, or you might get duplicate sends, which can confuse naive implementations like marking delivered, then getting another in-transit scan late. This problem multiplies in multi-tenant environments where events flow through shared infrastructure.
Adding timestamps to events helps consumers manage out-of-order events, allowing them to reorder or ignore events as needed and measure processing delays for better monitoring. But timestamps alone aren't sufficient for carrier integrations where network delays and API instabilities create significant timing skew.
The solution requires sequence numbering at the tenant level combined with partitioned delivery queues. Each tenant gets dedicated sequence counters per shipment, ensuring that even if global ordering breaks down, per-tenant per-shipment ordering remains intact.
Implementation Patterns: Queue Topology and Routing
The Publish-Subscribe (Pub/Sub) architectural pattern is highly recommended for building scalable webhook systems, where your application serves as publisher, sending events to a central message broker that delivers to subscribed consumers, decoupling producers from consumers to ensure scalability, reliability, and flexibility.
Queue sharding becomes essential for tenant isolation. This concept of sharded queue corresponds to multiple shards that can be seen as different queues, one per tenant, where services dequeue jobs from one of the shards in round-robin fashion. For carrier webhooks, this translates to dedicated retry queues per tenant with separate backoff policies, so when UPS's API starts timing out, only the affected tenant's webhook deliveries slow down while other tenants continue receiving real-time notifications for DHL and FedEx shipments.
Apache APISIX and similar API gateways provide HTTP-to-async conversion capabilities that work well for carrier webhook fan-out. The key architectural decision is whether to shard at the queue level (separate queues per tenant) or at the worker level (shared queues with tenant-aware workers). High-volume tenants benefit from dedicated infrastructure, while smaller tenants can share resources efficiently.
Dead Letter Queues and Retry Strategies by Tenant
Monitoring retry rates shows that high retry rates indicate issues with webhook delivery or recipient availability, can increase costs substantially, and an ideal retry rate should be less than 5%. But carrier integrations routinely see retry rates above 20%.
Carrier integration platforms routinely see retry rates above 20%, far higher than the ideal 5%, because carrier APIs suffer from endemic reliability issues that compound webhook delivery challenges. Ocean carriers like Maersk experience multi-hour API outages, LTL carriers return 5xx errors during peak periods, and FedEx maintenance windows can span entire nights.
The most effective retry pattern uses exponential backoff with jitter to prevent thundering herd problems: wait_time = min(base_delay * 2^attempt + jitter, max_delay). However, carrier-specific retry strategies work better than generic exponential backoff. When Hapag-Lloyd's API goes down for planned maintenance, it stays down for 4-6 hours—traditional backoff formulas become either too aggressive (wasting resources) or too conservative (missing narrow recovery windows).
Circuit breaker patterns become essential at the tenant level. Each tenant should have individual circuit breakers for each carrier, preventing cascading failures across the platform—when a tenant's Maersk integration fails repeatedly, their circuit breaker opens, but other tenants' Maersk webhooks continue processing normally.
Observability and Tenant-Level Metrics
Measuring delivery latency from webhook trigger to consumer receipt, with lower latency ensuring real-time updates, requires the ability to slice data based on tenant-id, destination URL, etc. This tenant-level observability becomes crucial when debugging multi-tenant webhook delivery issues.
OpenTelemetry integration for teams using observability platforms enables correlation with existing monitoring stacks, and observability and alerting about delivery failures can mean the difference between catching issues versus customers spotting them first. Correlation IDs become essential for tracing events across tenant boundaries and fan-out destinations.
Queue metrics require careful interpretation in multi-tenant contexts. Tracking message queue length helps identify backlogs and potential delivery delays, and if queue length is high along with high data change rates, you may need many days to drain the queue and should consider scaling workers/shards. But aggregate metrics hide per-tenant patterns—one tenant's ocean carrier integration failing can skew platform-wide statistics.
Solutions like Cargoson, MercuryGate, and Transporeon approach tenant-level observability differently. Some provide separate dashboards per tenant, others aggregate with tenant filtering. The key is ensuring tenant administrators can monitor their own webhook delivery health without exposing data from other tenants.
Security Considerations for Cross-Tenant Event Delivery
Following recommended cloud practices, including the Retry pattern, Circuit Breaker pattern, and Bulkhead pattern ensures that problems in the tenant's system don't propagate to your system. But security extends beyond failure isolation.
Webhook signature verification becomes more complex in multi-tenant environments. Each tenant might use different signing keys, and key rotation must happen independently. Webhooks should be cryptographically signed using public key infrastructure (PKI) with trusted parties signing certificates, some sending signatures in HTTP headers, others in JSON Web Tokens (JWT) with signature and claim, and if you can validate the payload, you can trust the publisher assuming their infrastructure hasn't been compromised.
SSRF (Server-Side Request Forgery) protection requires special attention in carrier webhook systems because tenant-specified endpoints might point to internal infrastructure. URL validation, IP address filtering, and request sandboxing become essential security controls.
Platforms like Cargoson, Descartes, and Blue Yonder implement different approaches to tenant isolation security. Some use network-level segregation, others rely on application-level controls. The choice depends on your compliance requirements and risk tolerance.
Capacity Planning and Burst Traffic Management
Peak shipping seasons create traffic spikes that test multi-tenant webhook architectures. Black Friday and holiday shipping can generate 10-50x normal event volumes, with different tenants experiencing peaks at different times.
If your platform generates 250 events per second during peak hours and delivery workers can push 50 webhook calls per second reliably, your buffer absorbs spikes while workers drain the queue at a stable rate—without this buffer, you would hit retry storms within minutes.
Auto-scaling decisions become more nuanced in multi-tenant environments. Do you scale based on aggregate queue depth or per-tenant metrics? Should high-volume tenants get dedicated workers, or can you achieve fairness through queue prioritisation?
The answer often involves tiered service levels. Enterprise tenants might get dedicated infrastructure and guaranteed processing capacity, while smaller tenants share resources with fair queuing algorithms. In some scenarios, you might provide different service-level agreements or quality of service guarantees to different tenants, with subsets expecting faster processing, using the Priority Queue pattern to create separate queues for different priority levels.
Effective multi-tenant webhook fan-out architectures for carrier integration require careful balance between isolation, performance, and cost efficiency. The patterns that work for generic SaaS platforms often break under the unique pressures of carrier APIs—higher failure rates, longer outages, and more unpredictable traffic patterns.
Success comes from recognising these domain-specific constraints and building architectures that embrace rather than fight them. Tenant isolation prevents one customer's carrier problems from affecting others, while sophisticated retry and circuit breaking patterns keep the system responsive even when individual carriers fail spectacularly.