Webhook Event Ordering for Carrier Integration: Architecting State Consistency When Delivery Events Arrive Out of Order

Carrier webhooks arrive out of order every single day across thousands of shipments. A tracking update from FedEx marked "delivered" shows up before the "out for delivery" event. UPS pickup confirmations lag behind dispatch notifications by hours. In 2026, major carriers including UPS, USPS, and FedEx will complete a shift that's been years in the making: retiring legacy carrier APIs in favor of more modern, secure platforms. Even after these migrations are complete, carriers will continue updating pricing logic, delivery data, security requirements, and services.
You can't pretend webhook event ordering for carrier integration is a solved problem when January 2026: USPS is switching off the last of its Web Tools APIs (Version 3) and June 2026: Remaining SOAP-based endpoints will be fully retired. Customers: Complete migration by June 1, 2026. These forced migrations create webhook chaos as teams scramble to rebuild integrations while maintaining shipment state consistency.
Why Traditional FIFO Webhook Patterns Fail During Migration Storms
Test how your system handles multiple rapid events, out-of-order events (sometimes a delayed "out for delivery" might arrive after a "delivered" in rare cases), and erroneous data. Sequential webhook processing destroys throughput during high-volume periods like Black Friday or when carrier systems catch up after downtime.
Sequential delivery patterns force you to process one webhook at a time, destroying parallelism. When USPS pushes 10,000 tracking updates after a system outage, your FIFO queue becomes a bottleneck. The frequency of these updates varies among carriers due to the rate limits set by each carrier. On average, users can expect updates within 2 hours of an event occurring.
The performance math is brutal. A synchronous webhook handler processing 1 webhook per second maxes out at 86,400 events daily. Meanwhile, parallel processing handles thousands per second. Data migration failure rates drop by 73% with proper planning, most teams are discovering these deadlines months too late.
The State-First Architecture: Webhook Events as Notifications, Not Truth
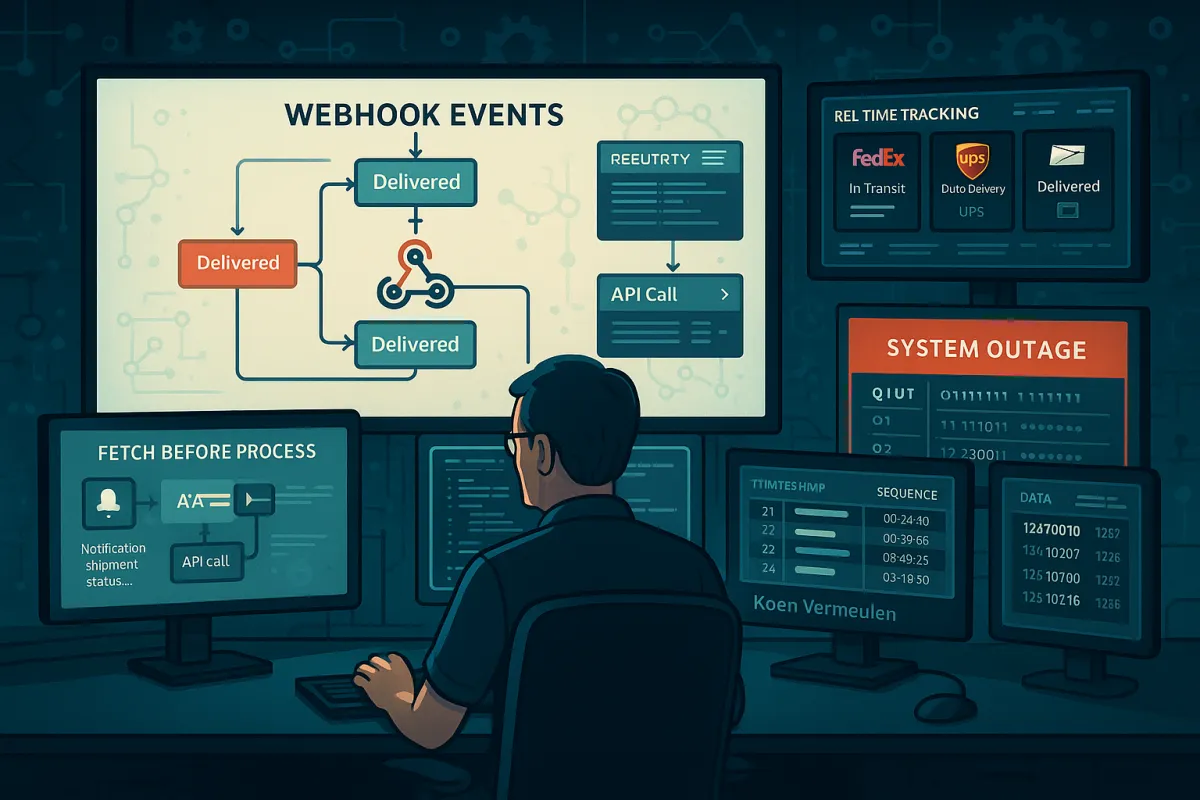
When building systems that consume webhooks, a common and robust pattern is to treat the incoming webhook as a notification, and then fetch the full, up-to-date resource from the provider's API before any processing takes place. This is known as the "Fetch Before Process" pattern. By fetching the latest state of a resource, you ensure your system is always working with the most current data, which simplifies your logic and enhances reliability.
Instead of trusting webhook payload data, use webhooks as signals to fetch current shipment state from carrier APIs. The core concept of the pattern is to treat the incoming webhook event as a signal to trigger a process, but instead of using the data in the webhook payload, you first make an API call to fetch the full, up-to-date resource. Fetching the resource from the API just before you process it helps solve these problems. It allows you to: Work with the most current data: You're no longer relying on the data snapshot in the webhook payload, which might be stale. Validate the resource's state: You can confirm the resource is in the expected state before taking action. Simplify idempotency: Your processing logic is based on the actual state of the resource, not the event itself.
This approach handles ordering problems naturally. When a "delivered" webhook arrives before "in transit", your fetch-before-process handler queries the carrier API and discovers the shipment is actually delivered. The ordering becomes irrelevant because you're working with authoritative state, not event sequence.
Enterprise platforms like Cargoson, Shippo, and EasyPost implement state-first processing by default. They maintain local shipment state that gets updated through periodic API polls, while webhooks trigger immediate state refreshes for real-time responsiveness.
Timestamp-Based Event Reconciliation for Late-Arriving Updates
Carriers send timestamps with webhook events, but these often reflect when the scan happened, not when the webhook was sent. A package scanned at 9 AM might generate a webhook at 11 AM due to processing delays. USPS has confirmed that, starting Wednesday, April 1, 2026, new access control requirements apply to package tracking data delivered through Tracking APIs, webhook subscriptions, and scan event extracts. USPS says that users who do not complete the required authorization steps may lose access to tracking data, which can lead to failed API calls, missing scan events, or rejected webhook notifications.
Build event reconciliation using carrier-provided timestamps and sequence numbers. Each webhook should include:
- Event timestamp (when the scan actually occurred)
- Webhook sent timestamp (when the carrier dispatched the webhook)
- Sequence number or event ID for ordering within the same timestamp
- Carrier facility code where the event occurred
Handle conflicts through timestamp precedence. If a webhook arrives with an event timestamp earlier than your current shipment state timestamp, treat it as a late-arriving historical event. Log it for audit purposes but don't update current state unless your business logic specifically requires historical reconstruction.
Per-Shipment Queue Architecture Without Global Blocking
Imagine a sudden burst of activity—like a flash sale or a large data import—that generates thousands of webhooks in a short period. If your system attempts to fetch the resource for every single incoming event, you can easily generate a high volume of API requests per second. This can exceed the provider's rate limits (e.g., Stripe's is typically 100 read requests per second), causing them to respond with 429 Too Many Requests errors. To get the benefits of the "Fetch Before Process" pattern without the risk of hitting rate limits, you can decouple webhook ingestion from processing using a queue. By introducing a queue, you absorb sudden spikes in webhook volume and ensure your application processes events at a steady, manageable pace.
Partition your webhook processing by shipment ID or tracking number. Each shipment gets its own logical queue, ensuring events for shipment A don't block processing of shipment B. Within each partition, maintain FIFO ordering while achieving system-wide parallelism.
Redis Streams or Kafka partitioning work well for this pattern. Hash the tracking number to determine partition assignment. Configure one consumer per partition to maintain ordering within shipments while scaling across the total partition count.
Here's the queue architecture that handles out-of-order webhooks without blocking:
- Webhook ingestion layer: Fast HTTP endpoints that write to queues immediately
- Partitioned message broker: Redis or Kafka with shipment-based partitioning
- Per-partition workers: Each maintains ordering for its assigned shipments
- State store: Authoritative shipment data with timestamp-based conflict resolution
- Dead letter queues: For webhooks that fail after retry exhaustion
Platforms like Cargoson, ShipEngine, and nShift use similar approaches to isolate webhook processing failures between different shippers while maintaining delivery guarantees within each tenant's shipments.
Multi-Tenant Event Isolation During the 2026 Migration Crisis
The 2026 carrier API migration deadline creates a perfect storm for webhook processing failures. The Web Tools API platform shut down on Sunday, January 25, 2026, marking just the beginning of a massive wave of carrier API retirements hitting enterprise integration teams. For the thousands of companies still running legacy integrations, this isn't just a technical upgrade. It's a forced march through production deployment hell.
Implement circuit breakers per carrier and per tenant to prevent webhook processing failures from cascading. When USPS webhooks start failing due to authentication changes, your FedEx webhook processing should continue normally.
Design tenant isolation boundaries:
- Separate webhook endpoints per tenant or use tenant ID routing
- Per-tenant error budgets and circuit breakers
- Isolated processing queues to prevent one tenant's volume spikes from affecting others
- Independent retry policies based on tenant SLA requirements
Enterprise shipping platforms like Cargoson, project44, and Descartes provide exactly this abstraction. They handle carrier API changes, manage authentication complexity, and provide unified interfaces that survive individual carrier migrations.
When FedEx changes webhook payload formats mid-migration, your system should gracefully handle both old and new formats during the transition period without breaking existing integrations.
Production Monitoring and Recovery for Webhook Ordering Systems
Webhooks fail silently. Without observability built into your infrastructure from day one, you won't know events are being dropped until a customer reports missing data. You need visibility into delivery success rates, end-to-end latency (p95 and p99), queue depth and drain time, error classification and alerting, and full request/response inspection for debugging.
Monitor webhook ordering health through:
- Event sequence gap detection per shipment
- Processing time percentiles by carrier and event type
- Out-of-order event rates and resolution success rates
- Queue depth and drain time during traffic spikes
- State consistency verification between webhook events and API polls
Build automated recovery procedures for common failure scenarios. When webhook event gaps are detected, trigger API polling to fetch missing state transitions. FedEx completed the republishing of missed events at 9:00 AM CT on March 10, 2026... Webhook service issues reported on March 4th and 5th, 2026 are resolved... FedEx resolved a degraded-service incident that delayed webhook event delivery...
Alert on patterns that indicate ordering problems:
- Shipments stuck in intermediate states for longer than expected transit times
- Event timestamps that are significantly newer than webhook receive timestamps
- Missing intermediate states (e.g., "delivered" without "out for delivery")
- Carriers reporting high retry rates to your webhook endpoints
Document recovery procedures for your operations teams. When carrier webhook systems fail during migrations, your monitoring should detect the outage and automatically switch affected shipments to polling-based tracking until webhook delivery resumes.
The webhook event ordering patterns described here form the foundation for resilient carrier integration during the ongoing API migration period. Teams that implement state-first processing, proper queue isolation, and comprehensive monitoring will maintain shipment visibility even when carriers struggle with their own system modernization efforts.
Start with the fetch-before-process pattern for immediate reliability gains, then add per-shipment queuing and monitoring as your integration volumes scale. Remember that webhook ordering is a symptom of distributed system realities, not a problem to be solved through perfect event sequencing.