Webhook Retry Queue Architecture for the 2026 Carrier Migration Wave: Multi-Tenant Patterns That Survive API Reliability Crises


The major carrier API migrations completing in 2026 reveal a harsh truth: USPS Web Tools APIs shut down January 25, 2026, while FedEx's remaining SOAP-based endpoints will be fully retired in June 2026. Yet beneath these well-documented migrations lies a deeper problem threatening webhook retry queue architectures.
Traditional webhook systems assume brief, predictable outages. A 2025 Webhook Reliability Report shows that "nearly 20% of webhook event deliveries fail silently during peak loads", while a SmartBear survey reveals 62% of API failures went unnoticed due to weak monitoring setups. These aren't edge cases - they're the new normal for carrier webhook systems under load.
The 72% failure rate within the first month for carrier webhook implementations exposes the gap between sandbox testing and production reality. The platforms offering webhook reliability alongside traditional players include Cargoson, EasyPost, ShipEngine, and nShift - but as we'll see, their sandbox promises don't translate to production performance.
The 2026 Migration Reality Check
USPS has been sending notifications that they are retiring their current Web Tools API platform on Jan 25, 2026. The legacy USPS Web Tools API platform will shut down on Sunday, January 25, 2026. After that date, all existing Web Tools API integrations will stop working.
This creates a perfect storm with FedEx's own migration timeline. 2022 – 2025: FedEx has been moving away from older SOAP-based APIs toward modern RESTful APIs, introducing new services, enhancements, and rate logic. Legacy FedEx Web Services WSDLs were disabled, replaced by FedEx REST APIs.
But here's what the migration announcements don't mention: carrier webhook reliability remains fundamentally broken. While typical webhooks maintain <5% retry rates, carrier webhooks fail at rates that would bankrupt a traditional SaaS platform. The business costs of webhook failures can be substantial, including lost sales, customer dissatisfaction, regulatory penalties, and operational disruption costs, and in carrier integrations, these failures happen far more frequently than other domains.
The scale of the problem becomes clear when you consider that over 90% of organizations report downtime costs exceeding $300,000 per hour, with this average holding true even for small and midsize businesses up to 200 employees. Ocean carriers like Hapag-Lloyd regularly schedule maintenance windows lasting 4-6 hours. LTL carriers throw 5xx errors during peak seasons. Last-mile providers go dark during storm recovery.
Why Traditional Retry Patterns Fail for Carriers
Standard exponential backoff assumes your system recovers within minutes. But carrier-grade failures operate on entirely different timescales. When Maersk's API goes down for scheduled maintenance, it's not coming back in 30 seconds.
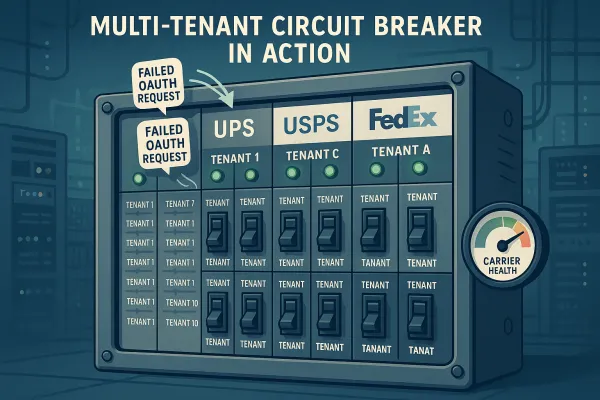
If one customer's endpoint slows down, you should never punish your other customers for it. This is the isolation pattern. This prevents "noisy neighbor" scenarios and helps your support team debug issues quickly. But most webhook retry architectures treat all failures the same way.
Consider the cascading effects: Customer A can respond in 40 ms, but Customer B regularly times out at 8 seconds. If both share the same global concurrency pool, Customer B's slowness will starve deliveries for A. But with customer-scoped schedulers, A continues receiving real-time webhooks even when B is failing repeatedly.
The isolation problem becomes severe in multi-tenant carrier middleware. One shipper's failed UPS webhook retries can consume queue capacity meant for a different tenant's time-sensitive FedEx notifications. This is the "noisy neighbor" problem in action, and it requires fundamental architectural changes to solve.
Multi-Tenant Queue Partitioning Architecture
The solution requires dedicated retry queues per tenant with round-robin dequeue patterns. This includes separate queues or partitions per tenant, per-tenant rate limits, and resource quotas that prevent any single tenant from monopolizing capacity. Tenant tiering offers different service levels at different price points.
Here's the architectural pattern that works at scale:
Sharded Queue Design: The silo model uses a separate queue for each tenant. This provides the highest level of isolation and data protection, but at higher cost, increased operational complexity, and lower agility. To fully isolate the flow of messages for tenants, we create a separate SQS queue for each tenant. The separate queues keep any one tenant from creating a bottleneck that can impact other tenants.
Tenant-Level Circuit Breakers: Each tenant gets their own circuit breaker per carrier. When UPS starts timing out for Tenant A, that doesn't affect Tenant B's DHL webhooks. The isolation boundary runs all the way down to the carrier level.
Resource Allocation Formulas: Calculate queue depth based on tenant tier and historical carrier outage patterns. Premium tiers get larger buffers. Budget tiers get basic retry limits but still maintain isolation. The math looks like:
- Queue Depth = Base Capacity + (Tier Multiplier × Expected Peak Volume)
- Retry Budget = Tenant SLA × Carrier Reliability Score × Time Window
- Circuit Breaker Threshold = Historical Failure Rate + Safety Margin
Platforms like Cargoson, alongside established players like nShift and Manhattan Active, implement variations of this pattern. The key insight: resource allocation must account for both tenant isolation and carrier-specific failure modes.
Adaptive Backoff for Carrier-Grade Failures
Standard exponential backoff: 1s, 2s, 4s, 8s, 16s, then give up. This works for typical API hiccups. It fails catastrophically for carrier maintenance windows.
Carrier-specific backoff requires different mathematical models:
Ocean Carriers: Long maintenance windows (4-6 hours) require extended backoff curves with jitter to prevent thundering herd recovery. Formula: `delay = min(base_delay * (2^attempt) + jitter, max_delay)` where max_delay can be 2 hours.
Parcel Carriers: Shorter outages but higher frequency during peak seasons. Faster initial retries with circuit breaker integration. Formula: `delay = base_delay * (1.5^attempt) + carrier_health_factor`.
LTL Carriers: Predictable daily maintenance patterns. Time-aware backoff that avoids retry storms during known maintenance windows. Formula includes time-of-day weighting.
The critical insight: An ideal retry rate should be less than 5%. But carrier integrations regularly see >20%. Adaptive backoff algorithms must account for this reality while preventing resource exhaustion.
Dead letter queue strategies vary by failure type. Authentication failures go to immediate manual review. Timeout failures enter extended retry cycles. Rate limit responses wait for specific cool-down periods. Connection failures trigger circuit breaker evaluation.
Production Monitoring and SLO Design
Carrier webhook monitoring requires metrics that traditional webhook systems ignore. This metric provides insight into the reliability of your webhook delivery system. Keep track of the rate of failed webhook deliveries and the types of errors encountered. Understanding error patterns helps in identifying and resolving issues promptly.
Essential Metrics:
- Delivery success % by provider (UPS vs FedEx vs DHL)
- End-to-end latency (p50/p95/p99) per carrier
- Queue depth by tenant and carrier
- Duplicate detection and idempotency hit rates
- Error classification (auth, timeout, rate limit, service unavailable)
Delivery Latency: Measure the time it takes for a webhook to be delivered from the moment it's triggered to the moment it's received by the consumer. Lower latency ensures real-time updates. You should have ability to slice this data based on tenant-id, destination URL, etc.
OpenTelemetry Patterns: Include tenant context and carrier identifiers in all traces. This allows debugging across the webhook delivery pipeline while maintaining tenant isolation. Trace headers should include: tenant_id, carrier_code, webhook_type, retry_attempt, circuit_breaker_state.
Key Differentiator Metrics: Initial delivery success rate separates reliable platforms from those dependent on retries. Retry storm resistance shows how well the system handles carrier outages. Authentication token persistence reveals whether the platform maintains stable carrier connections during high load.
Compare monitoring approaches: Cargoson focuses on per-tenant carrier health scores. nShift emphasizes aggregate throughput metrics. ShipEngine tracks retry queue depth as a leading indicator. EasyPost monitors authentication failure cascades. Each approach reveals different aspects of system health.
Migration Strategy and Risk Mitigation
Black Friday 2025 taught hard lessons about webhook reliability under load. Some platforms implemented undocumented auto-deactivation mechanisms when webhook delivery rates exceeded capacity. Customers discovered these "safety features" only when their integrations went dark during peak sales periods.
The platforms offering webhook reliability alongside traditional players include Cargoson, EasyPost, ShipEngine, and nShift - but as we'll see, their sandbox promises don't translate to production performance. The disconnect between sandbox and production behaviour suggests testing strategies must evolve.
Load Testing That Matters: Test webhook delivery at 10x expected peak volumes. Include carrier-realistic failure patterns: 4-hour maintenance windows, authentication token expiry, rate limiting during label storms. Sandbox APIs rarely exhibit these behaviors.
Preparing for Ongoing Changes: Even after these migrations are complete, carriers will continue updating pricing logic, delivery data, security requirements, and services. If you manage a custom-built site or a site built on a highly customizable platform like Magento, you may face ongoing development work, testing, and redeployments as carriers make changes to their API integrations.
Testing Strategies: Deploy canary webhook endpoints that receive 1% of live traffic. Monitor for silent failures, authentication cascades, and capacity throttling. Use synthetic transaction monitoring that mimics real carrier webhook payloads.
Risk mitigation requires multiple fallback layers. Primary webhook delivery through the new queue architecture. Secondary polling-based fallback for critical notifications. Tertiary manual intervention processes for compliance-sensitive shipments.
Implementation Patterns and Code Examples
Here's a concrete architecture diagram showing tenant-aware retry queue flows:
Webhook Event → Tenant Router → Tenant Queue (A|B|C)
↓
Per-Tenant Workers
↓
Carrier-Specific Circuit Breakers
↓
HTTP Delivery Attempt
↓
Success → Archive
Failure → Retry Queue (with backoff)
Circuit Open → Dead Letter Queue
Configuration Examples:
tenant_config:
premium_tier:
queue_depth: 10000
retry_limit: 8
circuit_breaker_threshold: 10
max_backoff: 7200 # 2 hours
standard_tier:
queue_depth: 5000
retry_limit: 5
circuit_breaker_threshold: 5
max_backoff: 1800 # 30 minutes
Adaptive Backoff Algorithm:
def calculate_backoff(attempt, carrier_type, tenant_tier):
base_delay = CARRIER_BASE_DELAYS[carrier_type]
tier_multiplier = TIER_MULTIPLIERS[tenant_tier]
if carrier_type == 'ocean':
# Long maintenance windows
delay = min(base_delay * (2 ** attempt), 7200)
elif carrier_type == 'parcel':
# Frequent shorter outages
delay = base_delay * (1.5 ** attempt)
else:
# Standard exponential
delay = base_delay * (2 ** attempt)
jitter = random.uniform(0.8, 1.2)
return int(delay * tier_multiplier * jitter)
Circuit Breaker Integration:
class TenantCarrierCircuitBreaker:
def __init__(self, tenant_id, carrier_code):
self.tenant_id = tenant_id
self.carrier_code = carrier_code
self.failure_count = 0
self.state = "CLOSED"
def should_allow_request(self):
if self.state == "OPEN":
if self.should_attempt_reset():
self.state = "HALF_OPEN"
return True
return False
return True
Reference implementations exist across multiple platforms. Cargoson's approach emphasizes tenant-level resource allocation. EasyPost focuses on carrier-specific retry logic. ShipEngine implements sophisticated backoff algorithms. nShift provides comprehensive circuit breaker integration. Each offers patterns you can adapt for your specific requirements.
The architecture succeeds when it treats carrier integration reliability as a first-class concern, not an afterthought. Multi-tenant isolation prevents cascade failures. Adaptive backoff handles carrier-grade outages gracefully. Comprehensive monitoring reveals problems before they impact customers. Together, these patterns create webhook retry queue architectures that survive the 2026 migration wave and beyond.